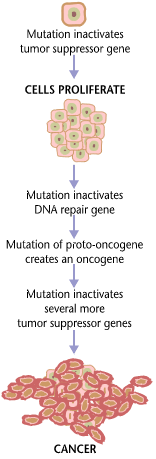
Genetic mutations can be benign or cancerous

Most of the roughly 40 trillion cells of your body have nearly identical copies of your genome — the DNA inherited from your parents, containing instructions for everything from converting food to energy to fighting off infections. Healthy cells become cancerous through harmful mutations in the genome. If a cell’s genome is damaged by ultraviolet light, for example, it can result in mutations that tell the cell to grow uncontrollably and form a tumor.
Identifying the genetic changes that cause healthy cells to become malignant can help doctors select therapies that specifically target the tumor. For example, about 25% of breast cancers are HER2-positive, meaning the cells in this type of tumor have mutations that cause them to produce more of a protein called HER2 that helps them grow. Treatments that specifically target HER2 have dramatically increased survival rates for this type of breast cancer.
Scientists can now readily read cell DNA to identify mutations. The challenge is that the human genome is massive, and mutations are a normal part of evolution. The human genome is long enough to fill a 1.2 million-page book, and any two people can have about 3 million genetic differences. Finding one cancer-driving mutation in a tumor is like finding a needle in a stack of needles.
I am a computer scientist who explores large and complex genetic data sets to answer fundamental questions about biology and disease. My research team and I recently published a study using DNA from thousands of healthy people to help identify disease-causing mutations by using the principle of natural selection.
Using big data to find cancerous mutations
When determining what type of cancer mutation a patient has, the gold standard is to compare two samples from the patient: one from the tumor and one from healthy tissue (typically blood). Since both samples came from the same person, most of their DNA is identical; focusing only the genetic regions that differ from each other drastically narrows the location of a possible cancer-causing mutation.
The problem is that healthy tissue isn’t always collected from patients, for reasons ranging from clinical costs to narrow research protocols.
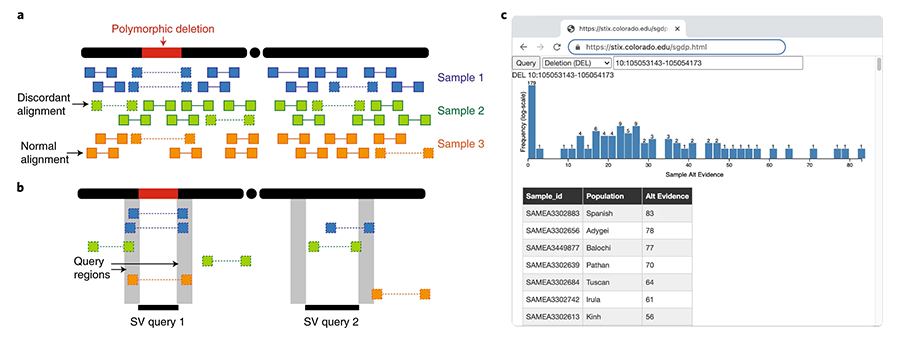
One way to get around this is to look at massive public DNA databases. Since cancer-driving mutations are detrimental to survival, natural selection tends to eliminate them over time in successive generations. Of all the mutations in a tumor, the ones that occur less frequently in a given population are more likely to be harmful than changes that are shared by many people. By counting how often a mutation occurs in these databases, researchers can distinguish between genetic changes that are common and likely benign and those that are rare and potentially cancerous.
{kind=link}
Given the power of this approach, there has been a recent surge of projects to collect and share the DNA sequences from hundreds to thousands of individuals. These projects include the 1000 Genomes Project, Simons Genome Diversity Project, GnomAD and All of Us. There will likely be many more in the future.
Estimating how likely a mutation causes disease by how frequently it appears in a genome is common for small genetic changes called single-nucleotide variants (SNVs). SNVs affect just one position in the 3 billion neuclotide human genome. It could, for example, switch one thymine T to a cytosine C.
Most researchers and clinical pathologists use a catalog of variants that have been detected across thousands of samples. If an SNV identified in a tumor is not listed in the catalog, we can assume that it’s rare and possibly drives cancer. This works well for SNVs because detection of these mutations is usually accurate, with few false negatives.
However, this process breaks down for genetic changes across longer strands of DNA called structural variants (SVs). SVs are more complex because they include the addition, removal, inversion or duplication of sequences. Compared to much simpler SNVs, SVs have higher error rates in detection. False negatives are relatively frequent, resulting in incomplete catalogs that make comparing mutations against them difficult. Finding a tumor SV that isn’t listed in a catalog could mean that it’s rare and a cancer-driving candidate, or that it was missed when the catalog was created.
Focusing on verification
My colleagues and I solved these problems by moving from a process focused on detection to one that focuses on verification. Detection is difficult — it requires processing complex data to determine if there is enough evidence to support the existence of a mutation. On the other hand, verification limits decision-making just to whether or not the evidence at hand supports the existence of a specific event. Instead of looking for a needle in a stack of needles, we are now simply considering whether the needle we have is the one we want.
Our method leverages this strategy by searching through raw data from thousands of DNA samples for any evidence supporting specific SV. In addition to the efficiency benefits of only looking at the data flanking the target variant, if there is no such evidence, we can confidently conclude that the target variant is rare and potentially disease-causing.
Using our method, we scanned the SVs identified in prior cancer studies and found that thousands of SVs previously associated with cancers also appear in normal healthy samples. This indicates that these variants are more likely to be benign, inherited sequences rather than disease-causing ones.
Most importantly, our method performed just as well as the traditional strategy that requires both tumor and healthy samples, opening the door to reducing the cost and increasing the accessibility of high-quality cancer mutation analysis.
My team and I are exploring expanding our searches to include large collections of tumors from different types of cancers such as breast and lung. Determining which organ a tumor originated from is critical to prognosis and treatment because it can indicate whether the cancer has metastasized or not. Because most tumors have specific mutational signatures, recovering evidence of an SV within a specific tumor sample could help identify the patient’s tumor type and lead to faster treatment.
![]() This article is republished from The Conversation under a Creative Commons license. Read the original article.
This article is republished from The Conversation under a Creative Commons license. Read the original article.
Enjoy reading ASBMB Today?
Become a member to receive the print edition four times a year and the digital edition monthly.
Learn moreGet the latest from ASBMB Today
Enter your email address, and we’ll send you a weekly email with recent articles, interviews and more.
Latest in Science
Science highlights or most popular articles
Mitochondria shape kidney cell function
Researchers at the University of Washington, Seattle present the first quantitative comparison of mitochondrial interactomes between two epithelial cell types in the kidney.

Long-chain polyunsaturated fatty acids linked to postoperative delirium risk
Researchers show that altered lipid metabolism may contribute to postoperative delirium, a condition linked to increased risk for long-term cognitive decline. The study explores potential disease mechanisms, which have yet to be understood.

Glycosylation patterns across antibody isotypes distinguish tuberculosis states
Researchers at Taipei Medical University present the first site-specific glycosylation analysis of immunoglobulins in elderly tuberculosis patients.
Blood glycome possibly predicts lifespan
Researchers at the University of Santiago de Compostela show that total serum N-glycome can predict mortality independent of traditional risk factors.

Building a better model for drug delivery across the blood–brain barrier
Industry and academic scientists collaborated to develop a rat with humanized iron-transport receptors, enabling research into iron homeostasis and drugs that cross the brain’s barrier.

Fat synthesis enzyme crucial for milk fat and newborn growth
Researchers found that a deficiency of the fatty acid synthesis enzyme stearoyl-CoA desaturase-1 reduced mammary gland function during lactation and caused low birth weight in newborns that were fed milk from enzyme-deficient glands.